Large Language Models explained briefly
A lightweight intro to LLMs, laying the foundation for the following lessons.
Imagine you happen across a short movie script that describes a scene between a person and their AI assistant. The script has what the person asks the AI, but the AI's response has been torn off.

Suppose you also have this powerful machine that can take in any text and provide a sensible prediction of what word comes next. You could then finish the script by feeding in what you have to the machine, seeing what it would predict to start the AI's answer, and then repeating this over and over with a growing script completing the dialogue.
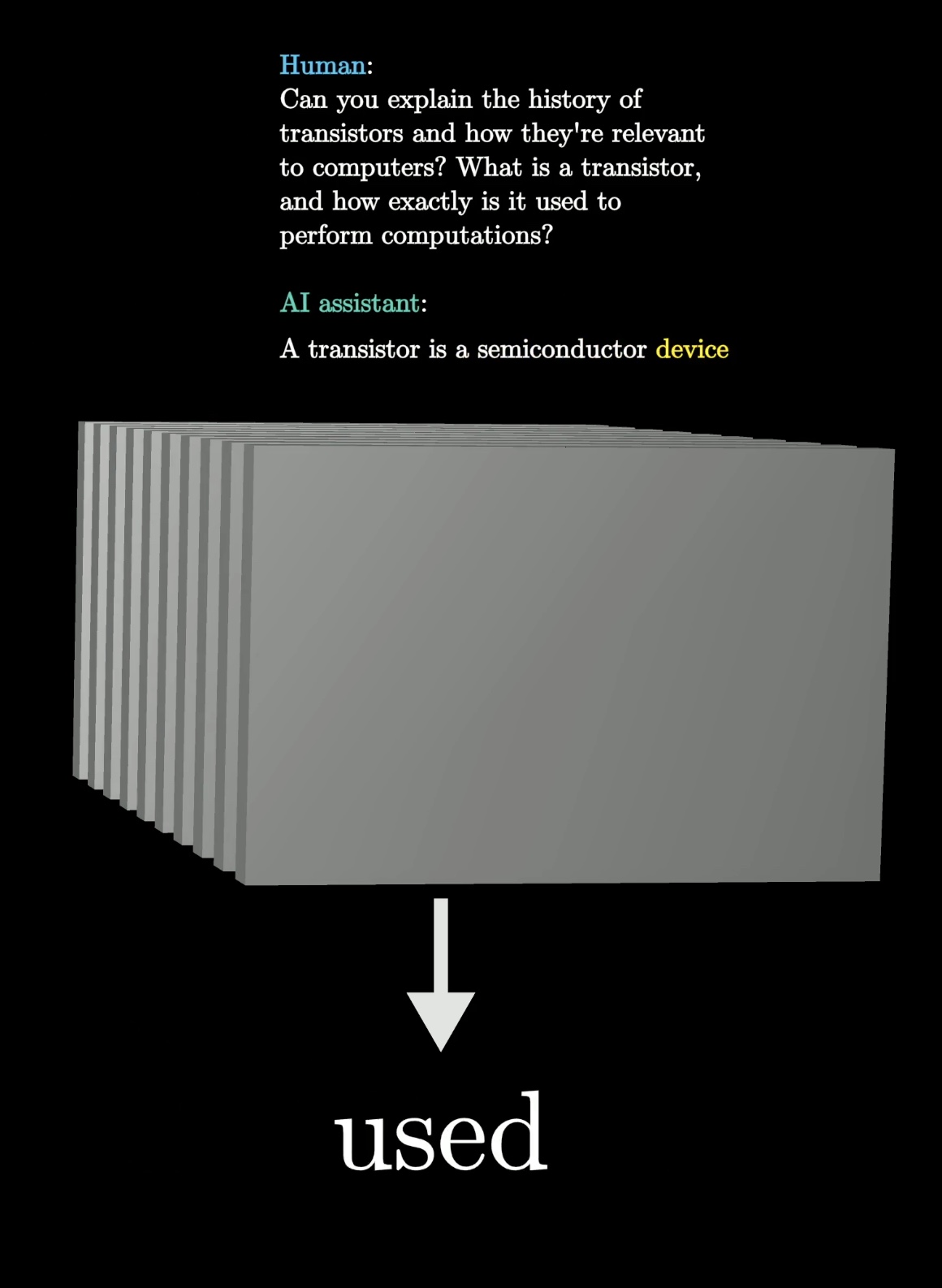
The machine, after being fed Can you explain...a semiconductor device..., predicts the word used.
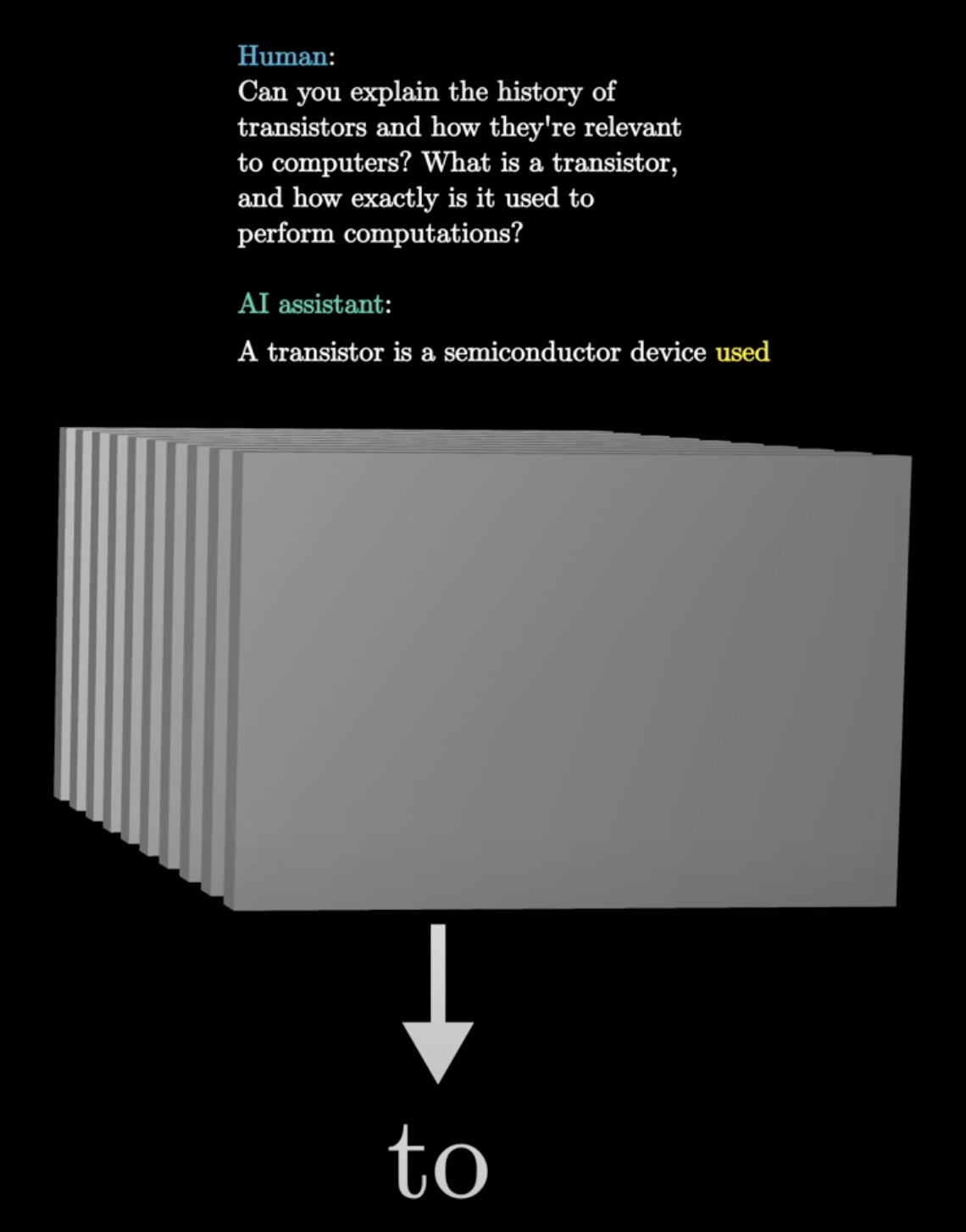
The machine, after being fed Can you explain...semiconductor device used..., predicts the word to.
When you interact with a chatbot, this is exactly what's happening.
What is an LLM?
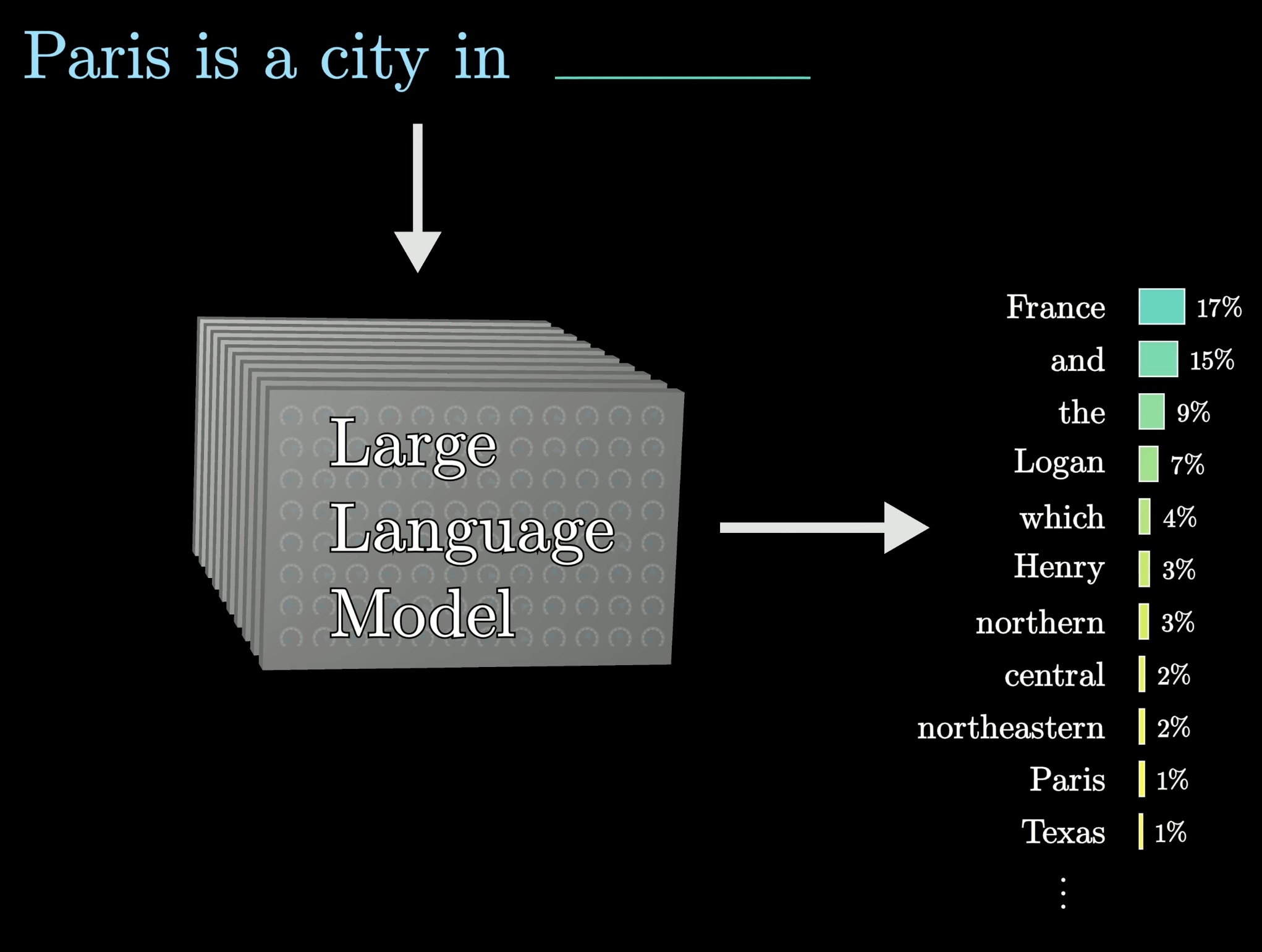
A large language model(LLM) is a sophisticated mathematical function that predicts what word comes next for any piece of text.
Instead of predicting one word with certainty, though, what it does is assign a probability to all possible next words.
To build a chatbot, you first lay out some text that describes an interaction between a user and a hypothetical AI assistant.

Then, you add on whatever the user types in as the first part of the interaction.

Finally, you have the model repeatedly predict the next word that this hypothetical AI assistant would say in response, and that is what's presented to the user.

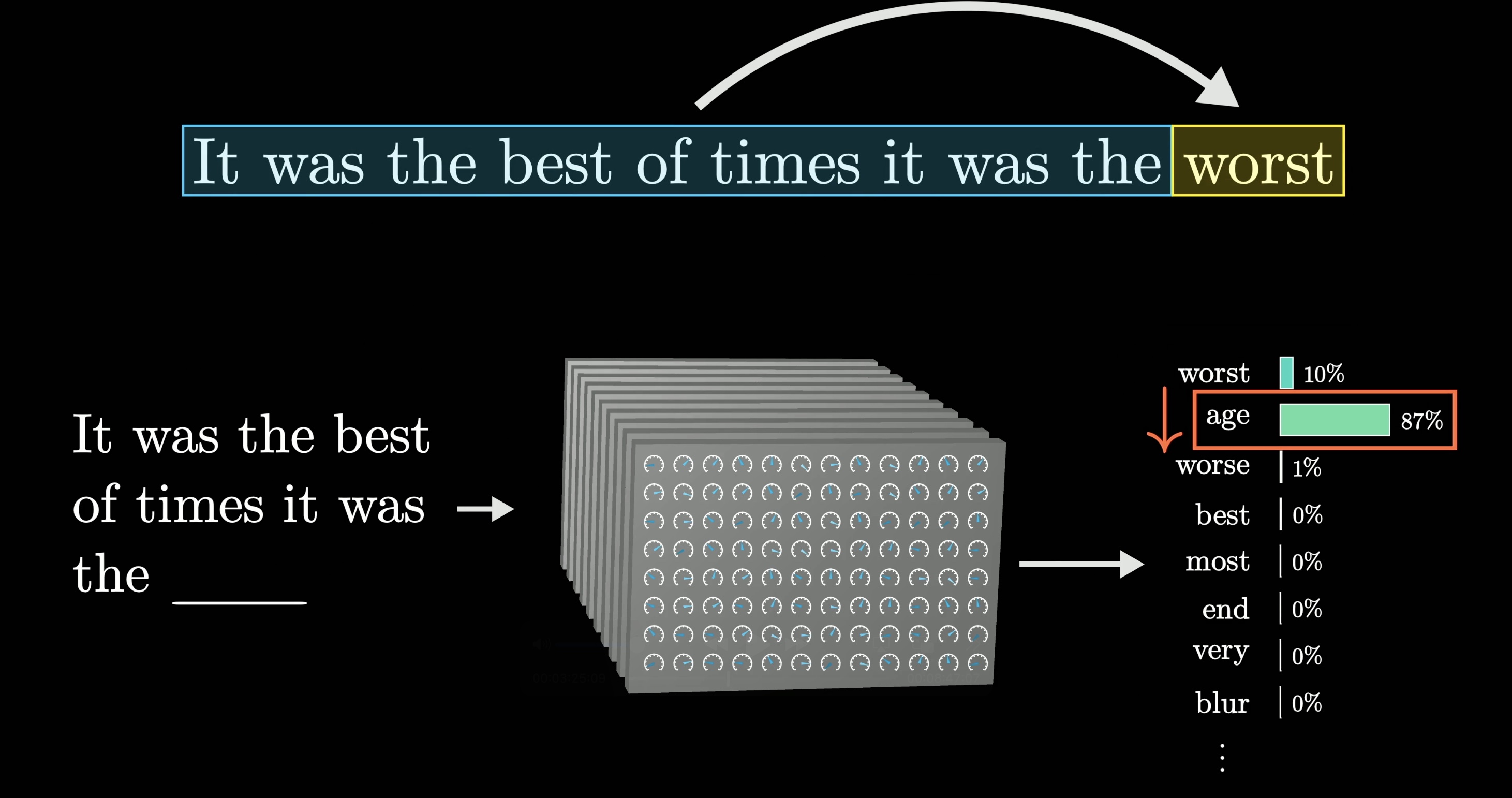
Feeding the model the green text and user input, as well as what the model has already generated, produces a probability distribution where the model selects the word option.
You might notice that, in the image, the model didn't select the most likely word. This isn't always the case, but is done by the model because the output tends to look a lot more natural if you allow it to select less likely words along the way at random.
What this means is even though the model itself is deterministic, a given prompt typically gives a different answer each time it's run.
How does an LLM predict the next word?
Models learn how to make these predictions by processing an enormous amount of text, typically pulled from the internet.

Fun fact: For a standard human to read the amount of text that was used to train GPT-3, they would need to read non-stop, 24-7, for over 2,600 years. Larger models since then, such as GPT-4, train on much, much more data.
Training a model can be thought of as tuning the dials on a really big machine. The way that a language model behaves is entirely determined by these many different continuous values, usually called parameters or weights.
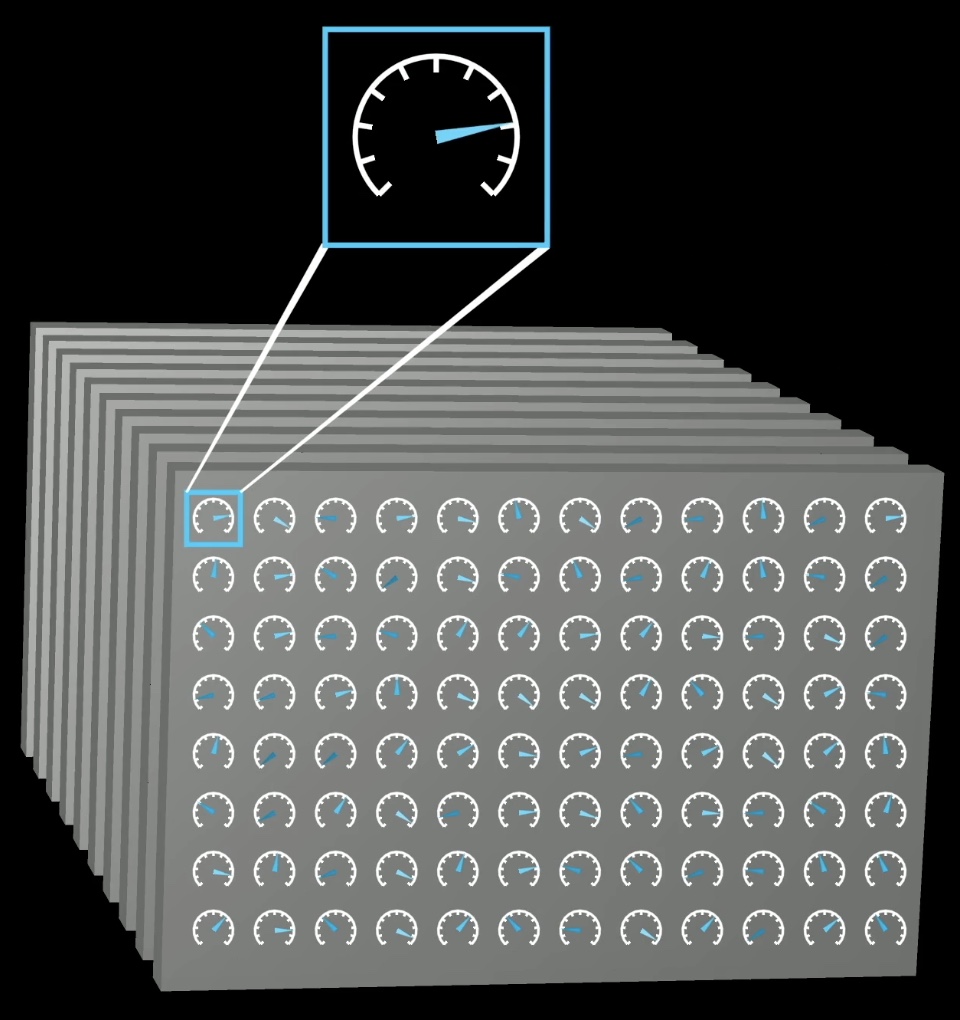
Changing these parameters is like changing the probabilities that the model gives for the next word on a given input.
What puts the large in large language model is how they can have hundreds of billions of these parameters.

No human ever deliberately sets those parameters, though. Instead, they begin at random, meaning the model just outputs gibberish. Then, they're repeatedly refined based on many example pieces of text.
These training examples could be just a handful of words, or they could be thousands of words. In either case, the way this training works is you pass in all but the last word from that example into the model and compare the prediction that it makes with the true last word from the example.
An algorithm called is then used to tweak all of the parameters in such a way that it makes the model a little more likely to choose the true last word and a little less likely to choose all the other words.

When this process is done for many, many trillions of examples, not only does the model start to give more accurate predictions on the training data, but it also starts to make more reasonable predictions on text that it's never seen before.
Given the huge number of parameters and the enormous amount of training data a model has to go through, the scale of computation involved in training a large language model is, to say the least, mind-boggling.
To put it into perspective, let's imagine that you could perform 1,000,000,000 additions and multiplications every single second. How long do you think it would take for you to do all of the operations involved in training the largest language models? A year? 10,000 years?
It will actually take you well over 100,000,000 years.
This process we just talked about is called pre-training, and is only part of training a chatbot goes through.

The goal of auto-completing a random passage of text from the internet is very different from the goal of being a good AI assistant. To address this, chatbots undergo another type of training, one just as important, called reinforcement learning with human feedback(RLHF).

Here, workers flag unhelpful or problematic predictions. Their corrections further change the model's parameters, making them more likely to give predictions that users prefer.
Looking back at the pre-training, though, this staggering amount of computations is only made possible by using special computer chips that are optimized for running many operations in parallel, known as GPUs.
But not all language models can be easily parallelized. Prior to 2017, most language models would process text one word at a time. Then a team of researchers at Google introduced a new model known as the transformer.
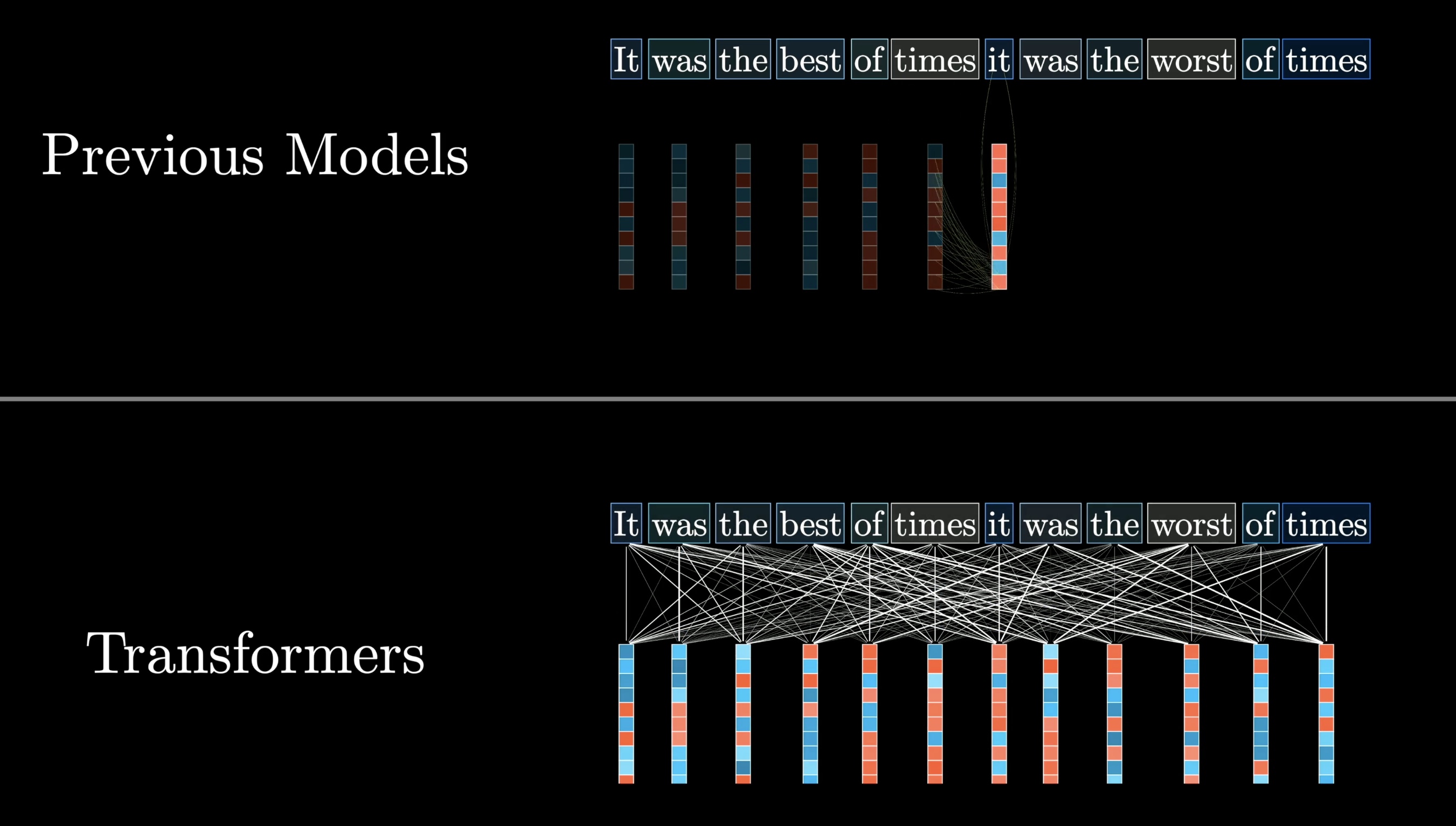
Transformers don't read text from the start to the finish, they soak it all in at once, in parallel.
Transformers
The very first step inside a transformer, and most other language models for that matter, is to associate each word with a long list of numbers. This is due to the fact that the training process only works with continuous values, so you have to somehow encode language using numbers.
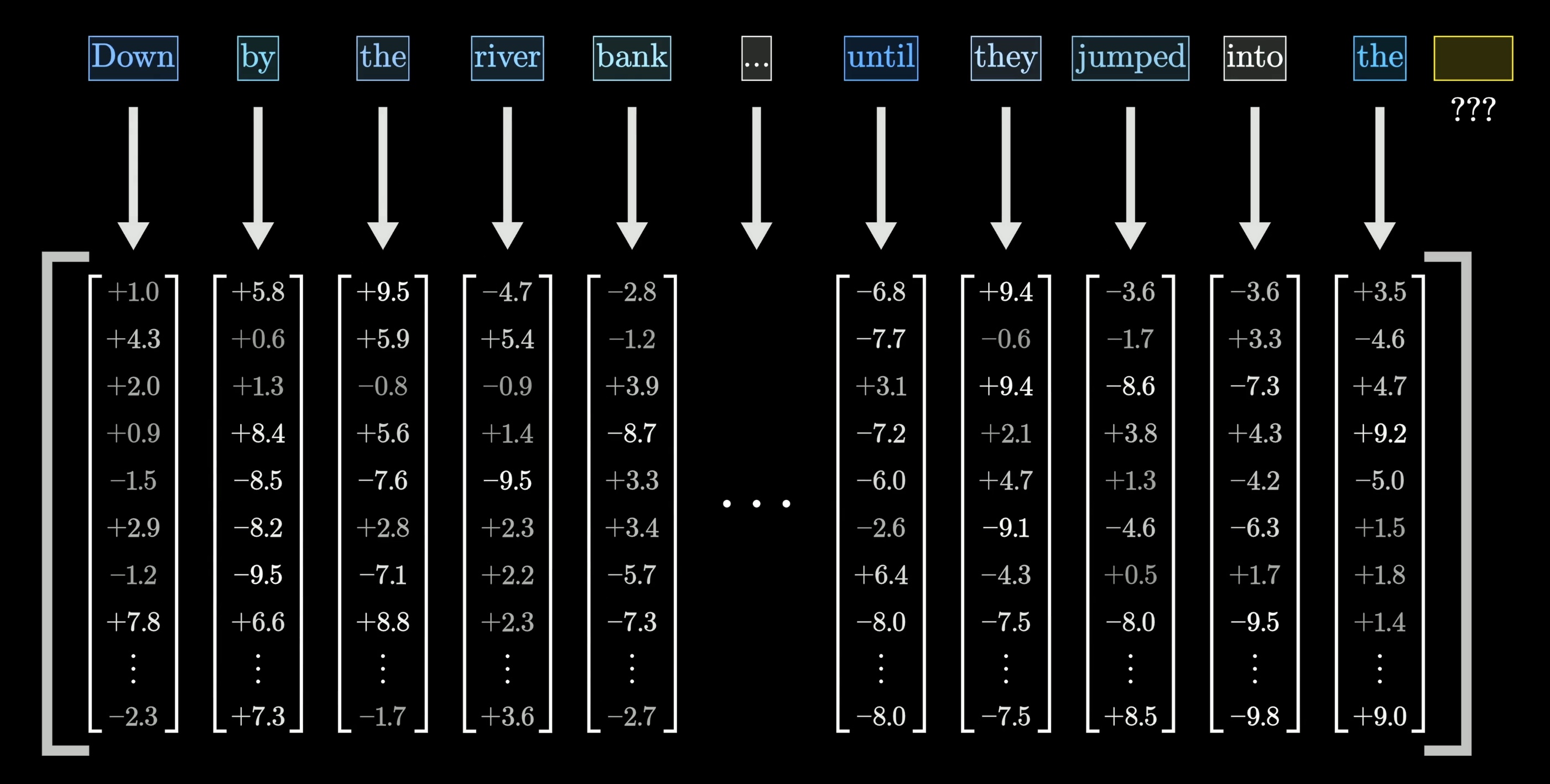
Each one of these long lists of numbers must somehow encode the meaning of the corresponding word.
What makes transformers unique is their reliance on a special operation known as . This operation gives all of these lists of numbers a chance to communicate with one another and refine the meanings they encode based on the context around, all done in parallel.
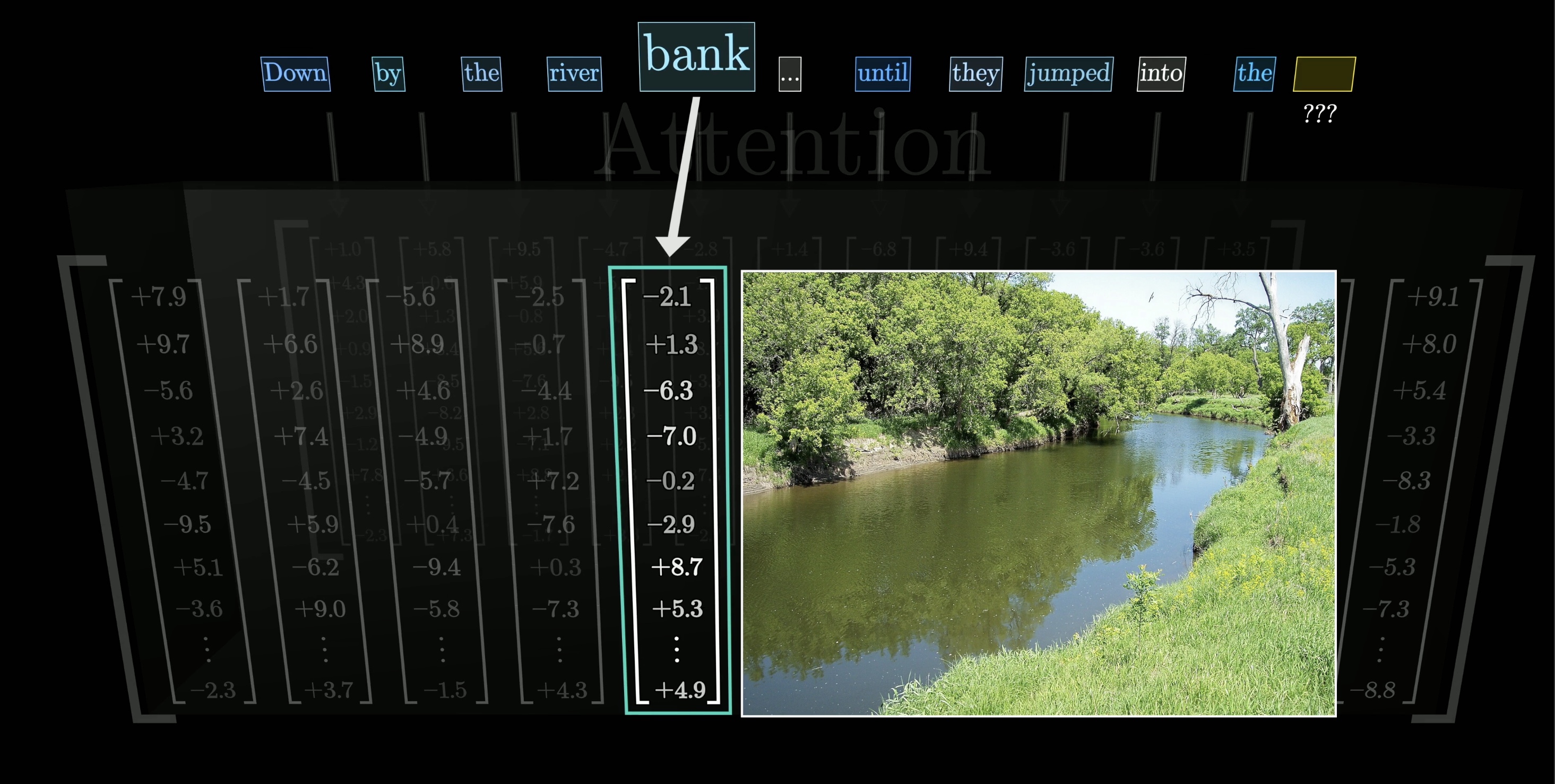
For example, in the image above, the numbers encoding the word bank might be changed based on the context surrounding it, like river and jumped into, to somehow encode the more specific notion of a riverbank.
Transformers typically also include a second type of operation known as a . This operation gives the model an extra capacity to store more patterns about language that it learned during training.
All of this data then repeatedly flows through many different iterations of these two fundamental operations. As it does so, the hope is that each list of numbers is enriched to encode whatever information might be needed to make an accurate prediction of the next word in the passage.
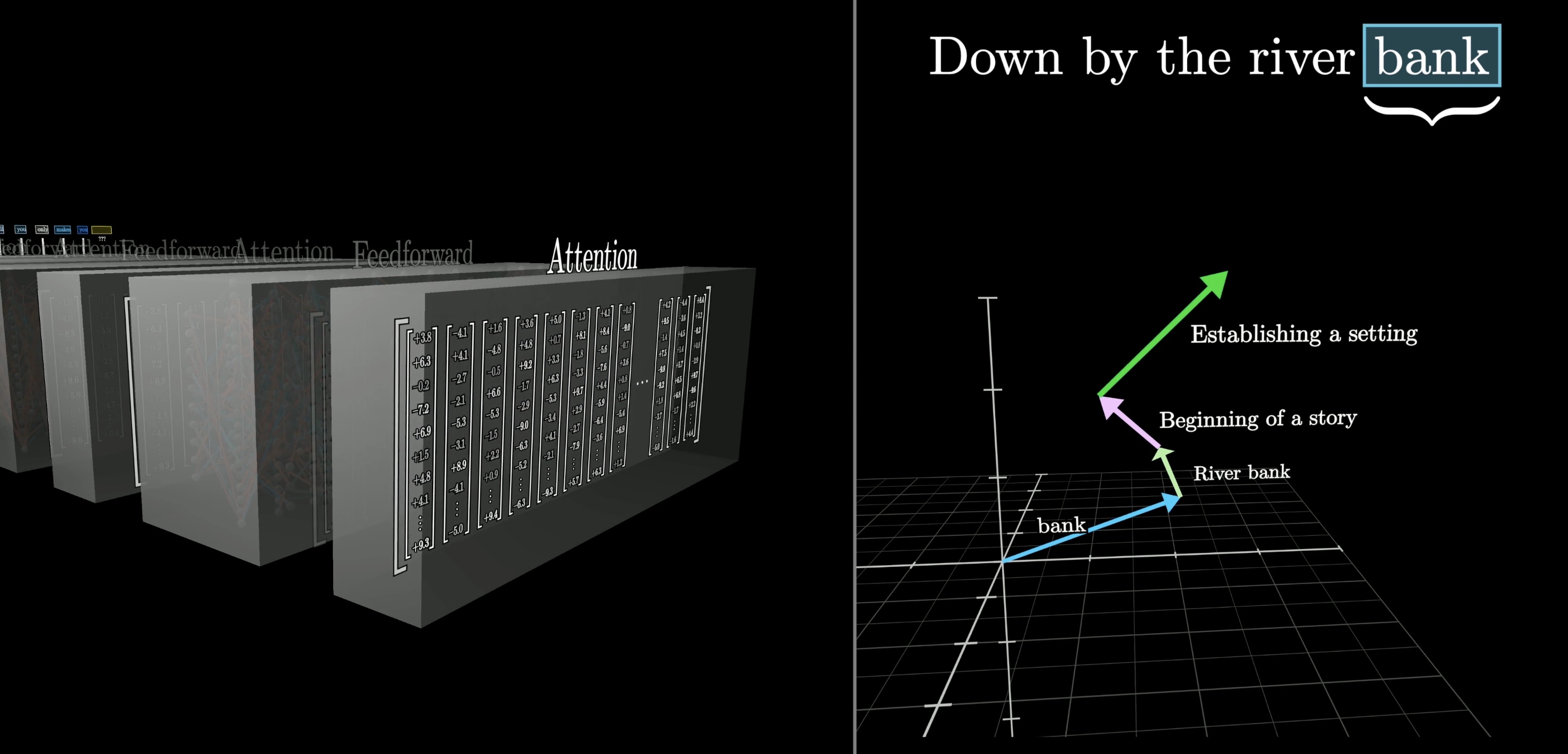
At the end, one final function is performed on the last vector in this sequence, which now has been updated by all of the context from the input text as well as everything the model learned during training, to produce a prediction of the next word.
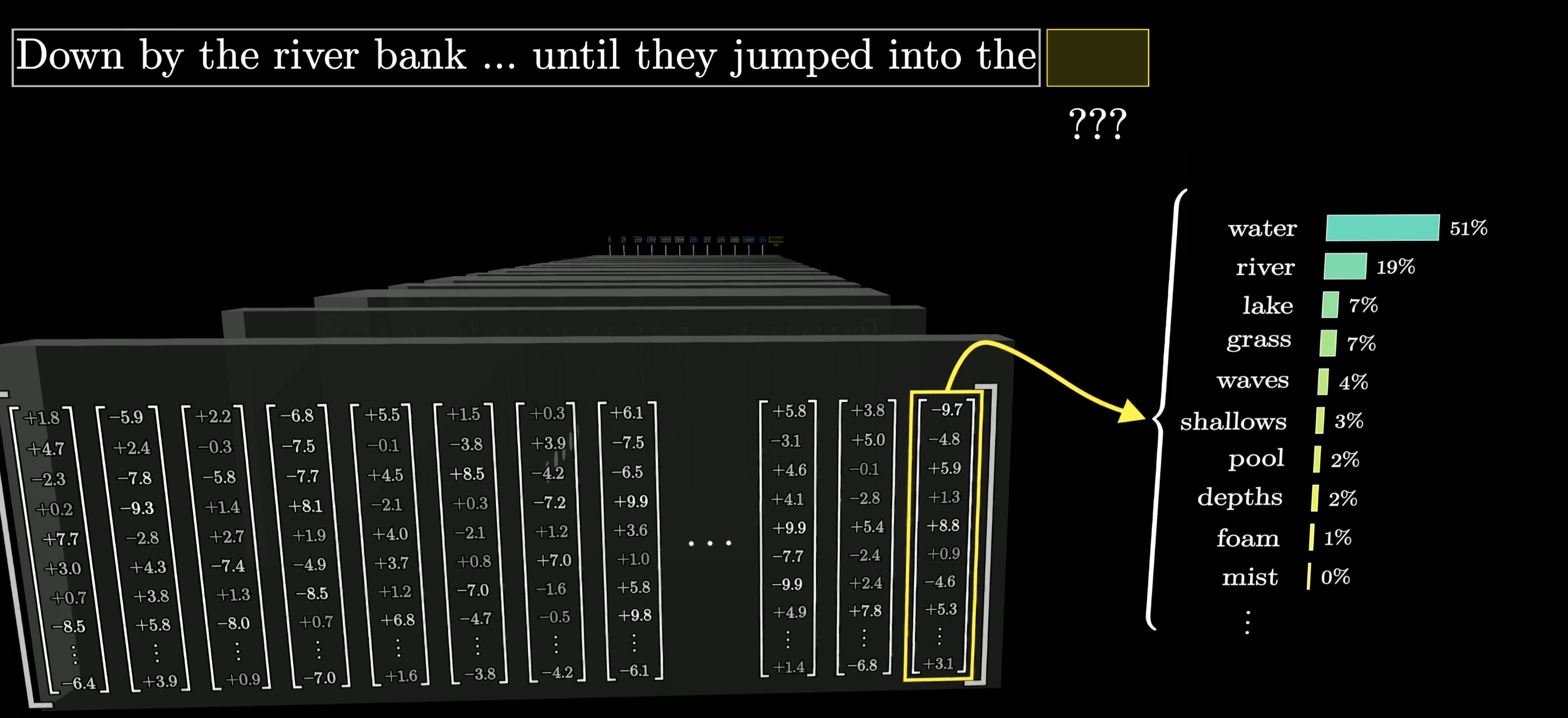
The model's prediction looks like a probability for every possible next word.
While researchers do design the framework for how each of these steps work, it's important to understand that the specific behavior is an emergent phenomenon based on how those hundreds of billions of parameters are tuned during training. This makes it incredibly challenging to understand why the model makes the exact predictions that it does.
More Resources
If, after this lesson, you're curious about more details on how transformers and attention work, here are some additional resources:
And here is a given to the company TNG about this topic: